VLM Explainer: From Patches to Phrases
Jan 1, 2025
·
1 min read
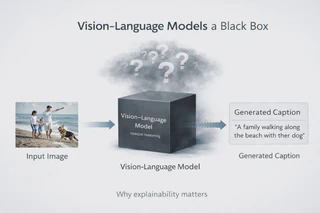
BLIP generates fluent captions but gives no account of why. The question this project answers: do the image regions the model highlights actually cause the caption, or do they just correlate with it?
Built Grad-CAM token attribution to identify which image regions influenced specific caption words. Validated through perturbation testing: masking the dog region changed “a family walking with their dog” to “a family walking on the beach.” Causal influence, not correlation, is the standard.
Added CLIP alignment scoring to cross-verify image-text grounding. Interactive Streamlit interface with 2-click region masking and layer-evolution visualization across shallow-to-deep BLIP representations.