Geometry-Grounded Novel-View Acoustic Synthesis
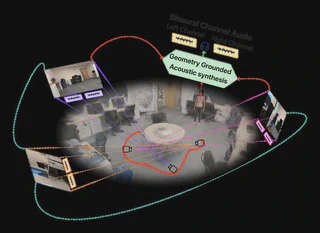
Prior audio-visual methods depend on Structure-from-Motion to build geometry: expensive, brittle with sparse frames, and unavailable at inference in many real scenes.
Built a feed-forward pipeline using VGGT geometry encoding and a cross-attention decoder that routes on geometry but retrieves learned acoustic priors. No COLMAP, no target-view image required.
Key architectural decision: separate keys and values in cross-attention so visual geometry decides which reference views are relevant, but the actual retrieved information is the learned acoustic fingerprint of those views, not the visual features themselves.
Outperformed prior SOTA (AV-Cloud) on all four metrics (MAG, ENV, LRE, DPAM) with fewer parameters (3.24M vs 3.91M) and 10x faster preprocessing than COLMAP.