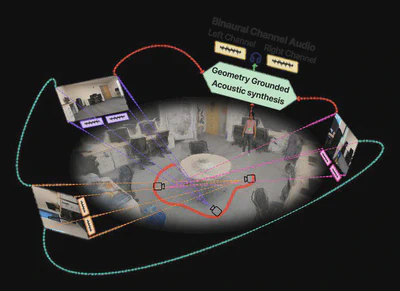
Geometry-Grounded Novel-View Acoustic Synthesis
Novel-view binaural audio synthesis without Structure-from-Motion. CVPR Workshop 2026.
I work on AI systems where the model is only part of the problem. That question shows up across computer vision, spatial audio, and vision-language models. Different domains, same question: what does it take for this to actually work outside the lab?
My current research is at CIVS, Purdue University, advised by Prof. Yang Ni and Prof. Chen Zhou, working on problems at the boundary of multimodal learning and real-world deployment.
A year and a half as an SRE across 11 global deployments shaped one instinct: understand how something works before building on top of it.
I am drawn to problems where the assumptions a method makes are themselves worth questioning, because that is usually where the next research question is hiding.
MSc Computer Science
Purdue University
BE Information Technology
LJ Institute of Engineering and Technology
Novel-view binaural audio synthesis without Structure-from-Motion. CVPR Workshop 2026.
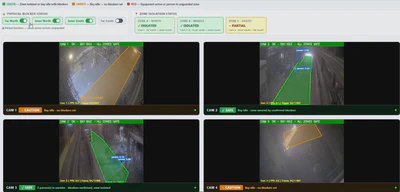
Real-time industrial safety monitoring with blind spot handling for steel melt shop environments.
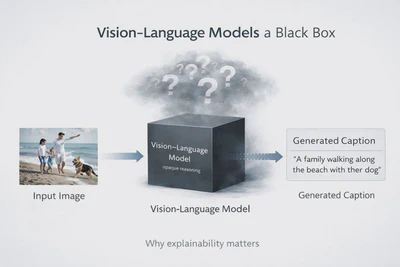
Causal explainability tools for vision-language model outputs using Grad-CAM, region masking, and perturbation testing.
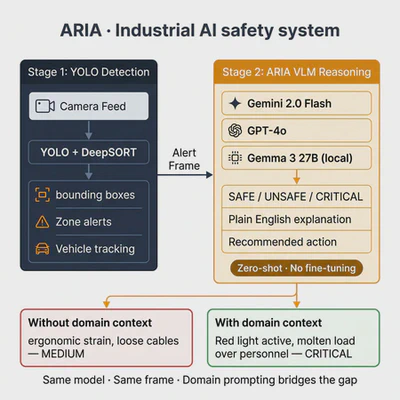
Domain-aware VLM reasoning for industrial hazard assessment in steel manufacturing environments.

Semantic resume ranking using MiniLM embeddings and cosine similarity, with LLM-generated match summaries.
Researching computer vision, spatial audio, and vision-language models.
Advised by Prof. Yang Ni and Prof. Chen Zhou.
Maintained 99% uptime SLA across 11 global production deployments (USA, UK, Canada, Australia, Hong Kong). 25+ services on Azure with strict regional isolation requirements.